Import und Daten-Transfer
Bei Mandanten-Setup oder Migration aus alten Systemen müssen oft große Daten-Mengen importiert werden — Kunden, Produkte, Lieferanten, historische Aufträge. SpeamCore bietet einen Import-Assistenten dafür.
Wann mache ich das?
- Initial-Setup eines Mandanten — Bestandsdaten aus Vorgänger-System.
- Massen-Updates — z.B. Preisliste eines Lieferanten.
- Periodische Backups — Daten-Export zur Sicherung.
- Datenanalyse — Export für Excel / BI-Tool.
So importieren Sie Daten
Import-Assistent öffnen
In der Sidebar Import-Assistent. Sie sehen die Liste vergangener Imports mit Status und Timeline.
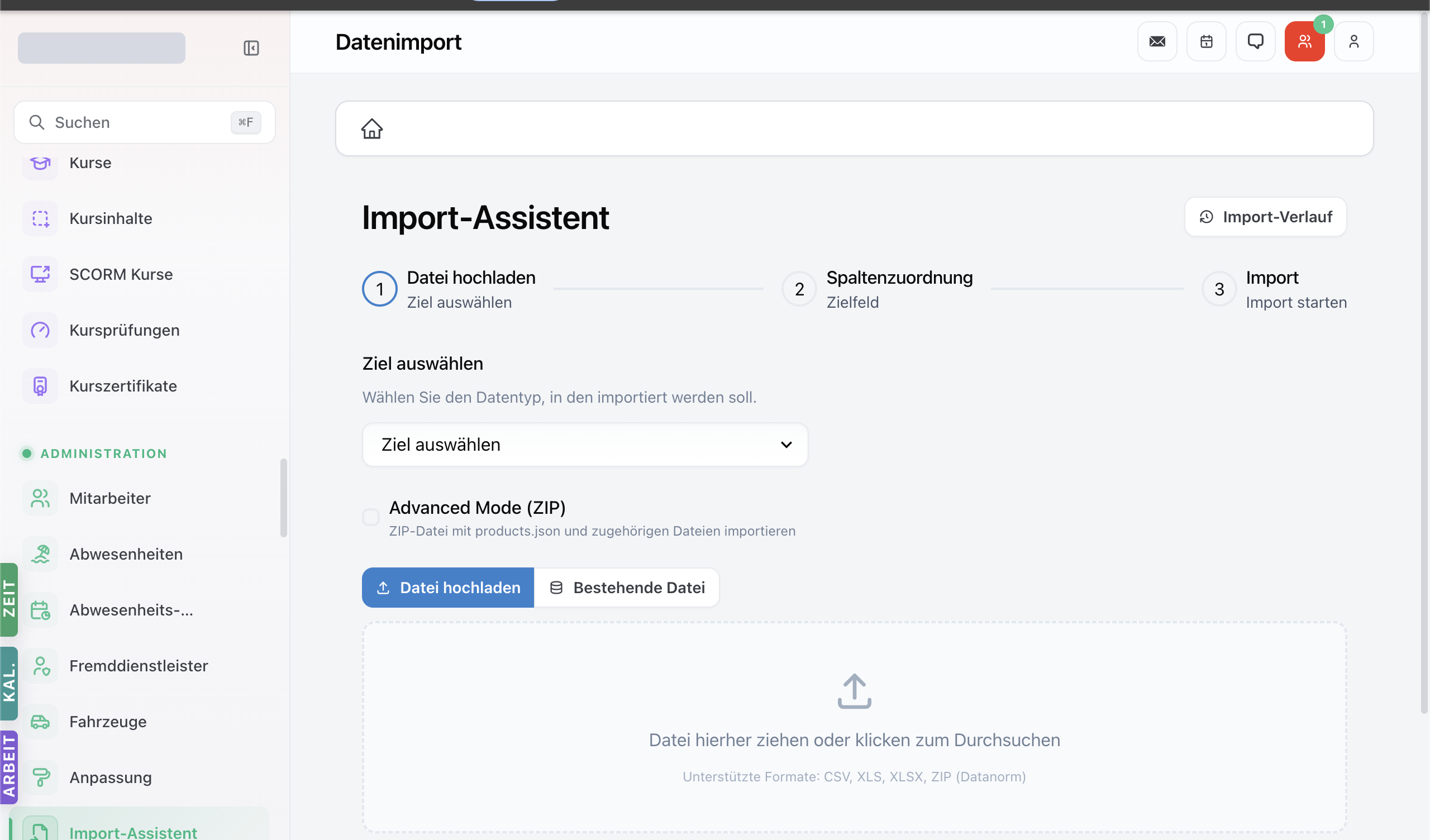
Klick auf + Neuen Import starten:
- Datentyp wählen — siehe Tabelle der unterstützten Datentypen unten.
- Datei hochladen — CSV, Excel, JSON.
- Encoding prüfen (UTF-8 standard).
Unterstützte Datentypen (CSV-Bulk-Import)
Der CSV-Bulk-Import (ausgebaut im Mai 2026) kennt aktuell 13 Ziel-Datentypen. Jeder Datentyp hat eine eigene Import-Konfiguration mit Pflichtfeldern und Identifikations-Logik:
| Datentyp | SpeamCore-Modell | Identifikation |
|---|---|---|
| Kunde | Customer | externalId + Name |
| Standort | Location | externalId (Name + Standort-Nr.) |
| Mitarbeiter | Employee | externalId (Name + E-Mail) |
| Niederlassung | Branch | externalId + Name |
| Lieferant | Supplier | externalId + Name |
| Auftrag | Workorder | externalId (Auftrags-Nr. + Status) |
| Verkaufsbeleg | SalesDocument | nur externalId |
| Verkaufsbeleg-Position | SalesDocumentItem | Beleg + Produkt-Nr. + Position |
| Arbeitszeit | EmployeeTimeTracking | nur externalId |
| Tätigkeit | EmployeeTimeTrackingType | externalId + Name |
| Einkaufsbeleg | PurchaseDocument | nur externalId |
| Einkaufsbeleg-Position | PurchaseDocumentItem | Beleg + Produkt-Nr. + Position |
| Zahlungsziel | PaymentTarget | externalId + Name |
Die fett markierten Typen sind im Mai 2026 neu hinzugekommen. Jede Zeile Ihrer Datei sollte eine Spalte _externalId mitführen — das ist der stabile Schlüssel, mit dem SpeamCore beim erneuten Import erkennt, ob ein Datensatz schon existiert (Update) oder neu ist (Anlegen).
Mapping pflegen
Im Mapping-Schritt verbinden Sie Quell-Spalten mit SpeamCore-Feldern:
- Source: „Firmenname" → Target:
Customer.name - Source: „PLZ" → Target:
Customer.zipCode - usw.
Pflichtfelder sind markiert — wenn nicht zugeordnet, wird der Import abgelehnt.
Default-Werte für nicht-vorhandene Spalten — z.B. status = 'active' für alle.
Vorab-Validierung — Mapping-Modal + DryRun (Welle 173)
Vor dem echten Import zeigt SpeamCore ein Pre-Import-Mapping-Modal, das die Datei analysiert ohne sie zu schreiben. Drei Farben pro Zeile:
| Farbe | Bedeutung | Aktion |
|---|---|---|
| 🟢 Grün | Datensatz wurde automatisch einem bestehenden Stammdatensatz zugeordnet (UPDATE) | nichts — passt |
| 🟡 Gelb | Neuer Datensatz, wird beim Import angelegt (CREATE) | prüfen ob das gewünscht ist |
| 🟠 Orange | Fuzzy-Match — mehrere mögliche Zuordnungen mit Ähnlichkeits-Score. Dropdown zur manuellen Auswahl | manuell zuordnen oder als neuen Datensatz übernehmen |
Funktioniert besonders für Stammdaten-Importe (Mitarbeiter, Niederlassung, Zahlungsziel — genau diese drei Typen nutzen die Fuzzy-Suche). Der Abgleich läuft wort-basiert:
- Ein führendes Zahlen-Präfix wird abgeschnitten (
036 Mölk Benjamin→Mölk Benjamin). - Reine Zahlen-Wörter und Wörter mit 1–2 Zeichen werden ignoriert.
- Pro möglichem Treffer zählt SpeamCore: passende Wörter ÷ Gesamtwörter = Ähnlichkeits-Score.
- Ab Score 0,5 (mindestens die Hälfte der Wörter passt) erscheint der Datensatz als Vorschlag im Dropdown.
- Ab Score 0,8 (mindestens 80 %) wird die Zuordnung automatisch übernommen (orange „Fuzzy"-Markierung) — Sie können sie im Dropdown trotzdem überschreiben.
Plus: DryRun-Checkbox „Vorschau (kein Import)" — wenn aktiv, läuft der komplette Import-Prozess durch (alle Zeilen, alle Validierungen, alle Mappings), aber ohne DB-Writes. Status dry_run_completed. Sie sehen am Ende ein Info-Banner mit:
- X Datensätze würden angelegt (Creates)
- Y Datensätze würden aktualisiert (Updates)
- Z Zeilen würden mit Fehler abgewiesen
Erst wenn DryRun sauber + Mapping-Modal bestätigt: Vollimport. Die Override-Entscheidungen aus dem Modal werden 1:1 in den Import übernommen.
Vollimport durchführen
Klick auf Import starten:
- Bei großen Imports (1000+ Zeilen): kann Minuten bis Stunden dauern.
- Background-Job — Sie können Tab schließen und später zurückkommen.
- Status-Tracking in der Import-Liste.
- Fehler-Details pro fehlgeschlagener Zeile.
Bei vielen Fehlern: Import abbrechen, Quell-Daten verbessern, neu starten.
Daten exportieren
In der Sidebar Datentransfer:
- Datentyp wählen (z.B. „Kunden komplett").
- Filter einschränken (z.B. nur aktive).
- Format wählen — CSV, Excel, JSON, DATEV.
- Export starten.
Bei großen Exporten ebenfalls Background-Job mit Download-Link nach Fertigstellung.
Backup-Strategie
Empfehlung:
- Wöchentlich Auto-Backup aller kritischen Daten.
- Vor größeren Aktionen (großer Import, Lösch-Aktionen) manuelles Backup.
- Backups extern speichern — nicht nur auf SpeamCore-Server.
- Recovery-Test halbjährlich — funktioniert die Wiederherstellung wirklich?
Weg 2 — Import-Diagnose per KI-Chat
Beispiel-Prompts (für Diagnose nach gescheitertem Import):
Mein letzter Kunden-Import (250 Datensätze) hat 47 Fehler erzeugt. Bitte
gruppiere die Fehler nach Typ (fehlendes Pflichtfeld, ungültiges Format,
Constraint-Verletzung) und schlage Korrekturen vor.
Welche Tabellen / Datentypen haben in den letzten 30 Tagen Import-Aktivität
gehabt? Mit Anzahl Datensätze und Fehler-Quote pro Import.
Was tue ich, wenn etwas schiefgeht?
Tipps
- Test-Mandant zum Üben — vor allem bei Initial-Migration.
- Mapping-Vorlagen speichern — bei wiederkehrenden Imports.
- Reihenfolge beachten — erst Lieferanten, dann Produkte, dann Kunden, dann Aufträge.
- Bei Großmigrationen externe Beratung — IT-Dienstleister mit SpeamCore-Erfahrung.
Verwandte Tutorials
- Anlagen und Standorte pflegen (Innendienst) — danach manuell ergänzen
- Settings und Customization
Für Entwickler: technische Details
- Modul: /import, /data-transfer.
- Background-Jobs: separater Worker + Queue für Import / Export.
- Mapping-Engine: konfigurierbar pro Datentyp (13 Entity-Configs).
- Format-Support: CSV, Excel (xlsx), JSON, DATEV (für Buchhaltung).
CSV-Bulk-Import-API (neu, Mai 2026 — eigene Route-Familie neben der älteren Import-Job-API):
| Methode | Endpoint | Zweck | CASL |
|---|---|---|---|
POST | /imports/upload | CSV hochladen + Job einreihen (CSV als String, Trennzeichen default ;) | create:ImportJob |
POST | /imports/preview | Trockenlauf-Vorschau ohne DB-Write | view:ImportJob |
GET | /imports | Job-Liste (paginiert) | view:ImportJob |
GET | /imports/:id | Job-Detail (Status, Fortschritt) | view:ImportJob |
PATCH | /imports/:id | Job abbrechen (status=cancelled) | update:ImportJob |
Der dryRun-Schalter wird im Upload-Body mitgegeben (nicht persistent gespeichert). Die Preview liefert summary (willCreate / willUpdate / willSkip / willError), eine matches-Liste und unmatchedRows mit possibleMatches. Post-Import-Hook refreshAddressSnapshot aktualisiert nach dem Import die denormalisierten Adress-Felder bei SalesDocument, PurchaseDocument und Workorder.